Optimizing Relational Databases for Best Performance in Mysql

English Version: For English version of this article, please visit: dev.to
Pengantar
Di dunia yang didorong oleh data saat ini, basis data relasional adalah tulang punggung dari aplikasi yang tak terhitung jumlahnya. Mereka menyimpan dan mengelola informasi penting, tetapi kinerja mereka dapat secara signifikan mempengaruhi pengalaman pengguna dan efisiensi sistem secara keseluruhan.
Posting blog ini membahas strategi kunci untuk mengoptimalkan basis data relasional dan memastikan mereka berjalan pada kinerja puncak.
🔍 Kesalahan Query Umum yang Menyebabkan Bottleneck
Sebelum mengoptimalkan, dalam penulisan ini diskusi hanya mencakup Full Table Scan yang Tidak Perlu, Query yang Tidak Efisien, Denormalisasi, Sumber Daya Hardware yang Tidak Cukup. Sangat penting untuk mengidentifikasi bottleneck kinerja. Berikut adalah beberapa penyebab umum:
1. Full Table Scan yang Tidak Perlu
Sebagai contoh, saya memiliki tabel products dengan total 4.000.000 baris data. Jika query Anda tidak memiliki indexing yang tepat, database mungkin dipaksa untuk membaca seluruh tabel untuk setiap pencarian. Misalnya bagaimana kita dapat mengetahui sebuah tabel terkena pemindaian tabel:
Di sini, saya dapat mencoba untuk memilih produk dengan kondisi nama
SELECT * from products WHERE name = "Produk 300665";
Dan hasil ini saya memiliki total waktu 0.628s, itu bukan waktu yang lama.
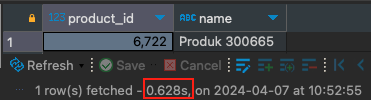
Tetapi hal yang mengejutkan adalah ketika Anda menjalankan explain untuk melihat apa yang terjadi:
explain SELECT * from products WHERE name = "Produk 300665";
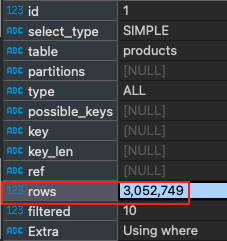
Lihat Anda telah membaca total 3.052.749 baris hanya untuk menemukan 1 baris data. Dan lihat kolom type di sini memiliki nilai ALL, artinya Anda membaca baris demi baris mencari data. Ini akan menjadi mimpi buruk ketika total data terus bertambah besar.
2. Query yang Tidak Efisien
Query SQL yang ditulis dengan buruk dapat memakan waktu lebih lama untuk dieksekusi dari yang diperlukan. Berikut adalah contoh query SQL yang ditulis dengan buruk:
SELECT * FROM orders WHERE YEAR(order_date) = 2024;
Query ini mengambil semua pesanan dari 2024. Namun, menggunakan fungsi YEAR() dalam klausa WHERE membuatnya tidak efisien karena mencegah query dari menggunakan indeks pada kolom Order Date.
Sebaliknya, ini memaksa database untuk menerapkan fungsi YEAR() ke setiap baris dalam tabel Orders, berpotensi menghasilkan pemindaian tabel penuh. Misalnya, di atas adalah cuplikan query dari tabel orders, sekarang mari kita lihat tabelnya.
orders saya memiliki indeks pada kolom order_date. Jalankan query ini untuk melihat daftar indeks yang tersedia:
show indexes from order_table;
Dan lihat saya memang memiliki indeks untuk kolom order_date.

Sekarang, ketika Anda menjalankan explain untuk melihat apa yang terjadi:
explain SELECT * FROM orders WHERE YEAR(order_date) = 2024;
Dapat dilihat dalam hasil di bawah ini, menggunakan fungsi seperti YEAR(), dapat menyebabkan indeks yang tersedia tidak digunakan.
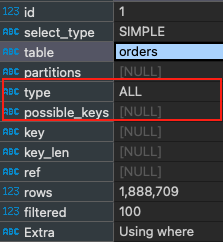
3. Denormalisasi (Pendekatan Hati-hati)
Dalam beberapa situasi, mendenormalisasi skema database Anda (memperkenalkan redundansi terkontrol) dapat meningkatkan kinerja query dengan mengurangi kebutuhan untuk join yang kompleks. Berikut adalah contoh sederhana untuk mengilustrasikan denormalisasi dalam MySQL:
Mari kita pertimbangkan skenario hipotetis di mana Anda memiliki dua tabel: users dan orders. Di bawah ini adalah Tabel Normalisasi Asli:
- tabel users dengan struktur:
user_id (Primary Key)
username
email
- tabel orders dengan struktur:
order_id (Primary Key)
user_id (Foreign Key mereferensi user_id dalam tabel users)
order_date
total_amount
Sekarang, katakanlah Anda sering perlu mengambil pesanan pengguna beserta dengan username dan email mereka. Cara yang paling umum adalah selalu menggabungkan tabel orders ke tabel users. Berikut adalah contoh query:
SELECT
orders.order_id,
users.name,
users.email,
orders.order_date,
orders.total_amount
FROM
orders
JOIN users ON orders.user_id = users.user_id;
Menggabungkan tabel-tabel ini setiap kali Anda membutuhkan informasi ini bisa menjadi bottleneck kinerja, terutama jika tabel-tabelnya besar.
Kami akan membahas cara mendenormalisasinya dalam bab solusi di bawah ini.
4. Sumber Daya Hardware yang Tidak Cukup
Kinerja database sangat bergantung pada faktor-faktor seperti CPU, RAM, dan kapasitas penyimpanan. Ini sangat sulit dilihat tanpa bantuan perangkat lunak pendukung. Kami akan membahas beberapa solusi di bawah ini.
🎯 Solusi
Setelah Anda mengidentifikasi bottleneck, Anda dapat menggunakan berbagai teknik untuk merampingkan database Anda:
1. Solusi Pemindaian Tabel Penuh yang Tidak Perlu
Indeks bertindak seperti jalan pintas untuk database, memungkinkannya untuk dengan cepat menemukan data spesifik. Membuat dan memelihara indeks secara strategis pada kolom yang sering digunakan dapat secara signifikan meningkatkan kecepatan query.
Menyelami Lebih Dalam ke Jenis-jenis Indexing
Dalam bidang manajemen database dan optimisasi, indexing memainkan peran penting dalam meningkatkan kinerja query. Memahami berbagai jenis indexing sangat penting untuk pengambilan dan manipulasi data yang efisien.
Mari kita selami lebih dalam ke dua jenis fundamental indexing: single index dan compound index, dan jelajahi fungsi mereka dengan contoh ilustratif.
Single Index:
Single index adalah mekanisme yang mudah di mana indeks dibuat pada satu kolom dari tabel database. Ini mempercepat proses pencarian dengan mengorganisir data dalam kolom yang diindeks dalam format terstruktur, sering kali B-tree atau hash table, memungkinkan pengambilan record spesifik yang lebih cepat.
Dalam contoh di atas, kami mencari nama dalam tabel products dengan jumlah data yang besar dalam tabel user. Ingat, untuk mencari 1 baris data, kami diminta untuk membaca setiap baris. Sekarang mari kita coba menambahkan single index ke kolom name dengan query berikut:
CREATE INDEX product_name_idx ON products (name);
Untuk melihat apakah indeks telah dibuat, jalankan query ini:
show indexes from users;
Ya, indeks telah dibuat:

Sekarang, coba lagi untuk memilih user dengan kondisi nama:
SELECT * from products WHERE name = "Produk 300665";
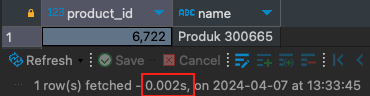
Dan sungguh menakjubkan betapa cepatnya Anda bisa mendapatkan data ketika Anda hanya membutuhkan 2 second untuk melakukannya, dibandingkan dengan waktu sebelumnya yaitu 0.628s detik.
Dan hal yang penting adalah bahwa kami memperhatikan berapa banyak baris yang dipindai. Silakan jalankan query ini lagi.
explain SELECT * from products WHERE name = "Produk 300665";
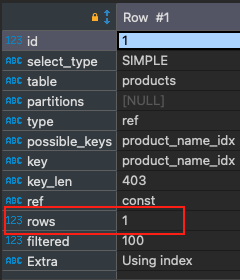
Hanya ada 1 baris yang dipindai dan Anda juga dapat mengamati bahwa kami menggunakan indeks. Catatan kecil, jika Anda ingin menghapus indeks dapat menjalankan query:
DROP INDEX product_name_idx ON product;
Composite Index:
Tidak seperti single index, composite index melibatkan pengindeksan beberapa kolom dalam tabel database. Jenis indexing ini sangat menguntungkan ketika query melibatkan kondisi pada beberapa kolom atau memerlukan pengurutan berdasarkan kombinasi field.
Memperluas contoh sebelumnya, katakanlah kita sering menjalankan query untuk mengambil produk berdasarkan nama, kategori, dan harga mereka.
Dalam skenario seperti itu, membuat indeks gabungan pada kolom nama, kategori, dan harga akan mengoptimalkan proses pencarian dengan menyimpan dan mengurutkan data berdasarkan kriteria gabungan ini.
Misalnya, jika kita ingin mencari users dengan nama spesifik, kategori (gadget), dan harga lebih besar dari 400.000, query akan terlihat seperti ini:
SELECT * from products WHERE name = "Produk 300665" AND category = "gadget" and price > 400;
Sebagai hasilnya kita mendapatkan 25 data.
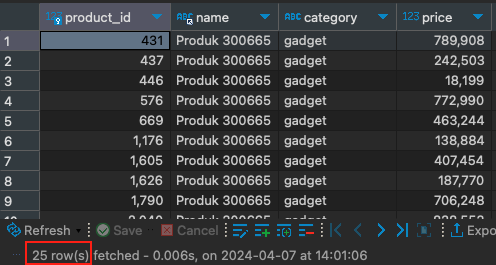
Lihat single index yang sebelumnya kita miliki tidak berpengaruh pada query dengan beberapa kondisi.
Jika kita menjelaskan dengan single index yang sebelumnya kita buat, kita membaca 28 baris:
explain SELECT * from products WHERE name = "Produk 300665" AND category = "gadget" and price > 400;
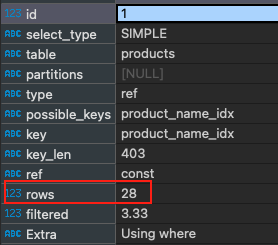
Jelas 25 baris diperoleh tetapi dengan membaca hanya 28 baris itu bukan masalah besar. Tetapi yang perlu kita ingat adalah apa yang terjadi jika kita memiliki data dalam jumlah besar. Tentu saja jumlah baris yang kita pindai akan jauh lebih besar dari data yang kita dapatkan. Dan sekarang kita mencoba membuat composite index, dengan menggabungkan beberapa kolom dalam 1 indeks, query seperti ini:
CREATE INDEX product_name_category_price_idx ON products (name, category, price);
Sekarang lihat, composite index telah dibuat:

Untuk membedakan antara single index dan composite index, lihat kolom key_name. Composite index adalah indeks dengan beberapa nilai column_name yang berbagi nama yang sama dengan indeks lain.
Dan sekarang, kita mencoba menjalankan query explain di atas untuk melihat hasil yang berbeda:
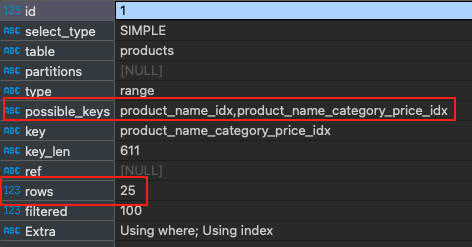
Voila, kita hanya membaca 25 baris untuk 25 hasil menggunakan composite index. Dan composite index yang kita miliki juga termasuk dalam daftar indeks yang akan kita gunakan.
2. Solusi Query yang Tidak Efisien
Menulis query SQL yang bersih dan dioptimalkan sangat penting. Teknik seperti menghindari fungsi kompleks dalam klausa WHERE dan menggunakan JOIN yang tepat dapat membuat perbedaan besar. Atau seperti dalam contoh di atas, menggunakan fungsi YEAR untuk mengurutkan tahun.
Versi yang lebih efisien dari query ini akan secara langsung membandingkan kolom order_date dengan rentang tanggal di 2024:
SELECT * FROM Orders WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01';
Lihat tidak ada yang terjadi dan tidak ada yang tampak aneh. Tetapi mari kita coba menjalankan query explain:
EXPLAIN SELECT * FROM Orders WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01';
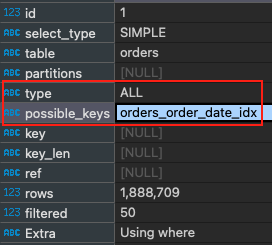
Sekarang indeks digunakan, dan ini sangat penting ketika data yang kita pindai sangat besar.
3. Solusi Denormalisasi
Untuk mengoptimalkan skenario ini menggunakan denormalisasi, Anda mungkin menambahkan kolom redundan dari tabel users ke dalam tabel orders:
Tabel Orders yang Didenormalisasi:
tabel orders:
order_id (Primary Key)
user_id (Foreign Key mereferensi user_id dalam tabel users)
order_date
total_amount
name (Kolom redundan dari tabel users)
email (Kolom redundan dari tabel users)
Dengan menambahkan kolom name dan email ke tabel orders, Anda menghilangkan kebutuhan untuk join yang sering ketika melakukan query data pesanan spesifik pengguna. Ini dapat secara signifikan meningkatkan kinerja query yang mengambil pesanan beserta informasi pengguna.
Sekarang query yang kita miliki hanya berurusan dengan tabel orders, tanpa menggabungkan tabel users dan memiliki hasil yang sama.
SELECT
orders.order_id,
orders.name,
orders.email,
orders.order_date,
orders.total_amount
FROM
orders;
Namun, penting untuk dicatat bahwa denormalisasi datang dengan trade-off.
Ini dapat menyebabkan redundansi data, peningkatan persyaratan penyimpanan, dan potensi inkonsistensi data jika update tidak dikelola dengan baik. Oleh karena itu, denormalisasi harus digunakan secara bijaksana dan dalam situasi di mana manfaat kinerja lebih besar daripada kerugiannya.
Selain itu, data yang didenormalisasi harus dijaga konsistensi melalui praktik manajemen data yang tepat seperti trigger atau logika aplikasi.
4. Sumber Daya Hardware yang Tidak Cukup
Untuk memantau kinerja Sumber Daya Hardware yang Tidak Cukup, pertimbangkan untuk menggunakan alat pemantauan pihak ketiga yang dirancang khusus untuk pemantauan kinerja MySQL.
Alat seperti MySQL Enterprise Monitor, Percona Monitoring and Management (PMM), New Relic, atau solusi open source seperti Prometheus dengan MySQL Exporter dapat menyediakan kemampuan pemantauan yang komprehensif.
📋 Kesimpulan
Mengoptimalkan basis data relasional sangat penting untuk memastikan kinerja optimal dan memberikan pengalaman pengguna yang lancar. Dengan mengatasi bottleneck umum seperti pemindaian tabel penuh yang tidak perlu, query yang tidak efisien, trade-off denormalisasi, dan sumber daya hardware yang tidak cukup, Anda dapat secara signifikan meningkatkan kecepatan dan efisiensi database MySQL Anda.
Strategi kunci termasuk teknik indexing cerdas seperti single dan composite index, menulis query SQL yang bersih dan optimal, dan penerapan denormalisasi yang bijaksana ketika manfaat kinerja lebih besar daripada kerugiannya. Selain itu, berinvestasi dalam sumber daya hardware yang memadai dan memanfaatkan alat pemantauan dapat membantu mengidentifikasi dan menyelesaikan masalah kinerja secara proaktif.
Dengan menerapkan strategi optimisasi ini, Anda dapat membuka potensi penuh dari basis data relasional Anda, memastikan pengambilan data yang sangat cepat, manipulasi data yang efisien, dan pengalaman aplikasi yang responsif untuk pengguna Anda.
Terima kasih, semoga membantu. 👋